Dalam statistik inferensial, metode analisis dapat dibedakan menjadi dua kelompok besar, yaitu statistik parametrik dan statistik non-parametrik. Pemilihan metode ini berpengaruh pada validitas hasil analisis karena masing-masing memiliki asumsi dan prinsip kerja yang berbeda. Meskipun keduanya bertujuan untuk menarik kesimpulan dari data sampel ke populasi, perbedaan pendekatan dapat memengaruhi akurasi dan kekuatan analisis.
10.1 Asumsi Parametrik
Metode analisis parametrik bekerja dengan optimal jika data memiliki distribusi normal (lihat Bab 9). Karena berbagai prosedur parametrik—seperti estimasi parameter dan pengujian hipotesis—mengandalkan sifat distribusi normal, penyimpangan yang besar dari normalitas dapat membuat hasil analisis menjadi bias atau kurang akurat. Oleh karena itu, sebelum menggunakan metode parametrik, peneliti perlu memeriksa apakah data mendekati distribusi normal melalui uji statistik maupun pemeriksaan visual.
Pemeriksaan melalui metode visual bisa dilihat berdasarkan kurva sebaran data. Salah satu yang paling umum digunakan adalah grafik histogram. Jika histogram tampak seperti lonceng, maka distribusi data tersebut dikatakan normal. Sebaliknya, jika terdapat kemiringan sehingga kurva terlihat jelas tidak simetris, maka data tidak terdistribusi dengan normal (lihat Gambar 10.1).
Metode pengujian statsitik dapat menjadi cara yang paling akurat untuk menentukan normalitas distribusi data (Field, 2018; Tabachnick & Fidell, 2019). Terdapat dua uji statistik yang cukup umum digunakan digunakan dalam konteks riset ilmu sosial, yaitu Kolmogorov-Smirnov (KS) dan Shapiro-Wilk (SW). Sejumlah studi mengungkapkan bahwa uji SW lebih andal dibanding KS karena memiliki daya uji (power) yang lebih tinggi dalam mendeteksi berbagai bentuk penyimpangan dari normalitas, baik akibat skewness maupun kurtosis, pada hampir semua ukuran sampel dan jenis distribusi (Oktaviani & Notobroto, 2014; Razali & Wah, 2011; Yap & Sim, 2011). Selain itu, KS cenderung kurang powerful untuk sampel kecil (Ghasemi & Zahediasl, 2012). Oleh karena itu, tes SW lebih disarankan untuk digunakan dalam pengujian normalitas distribusi data.
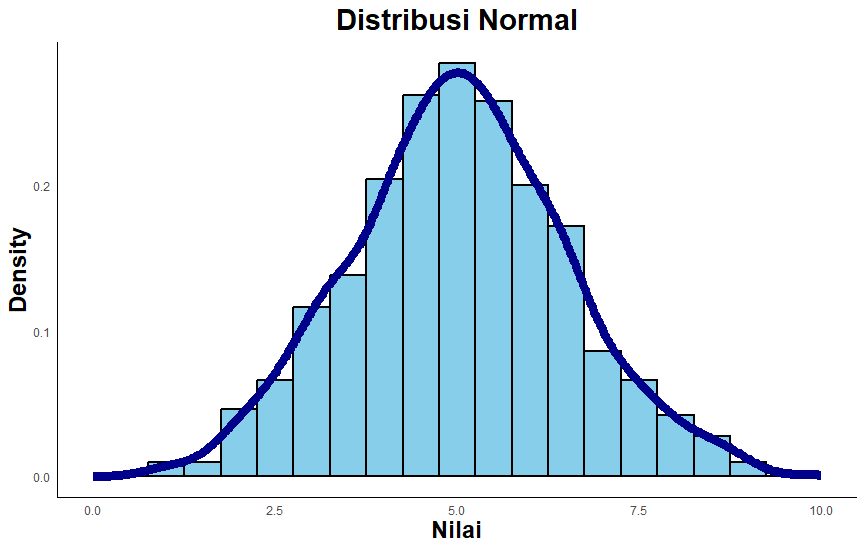
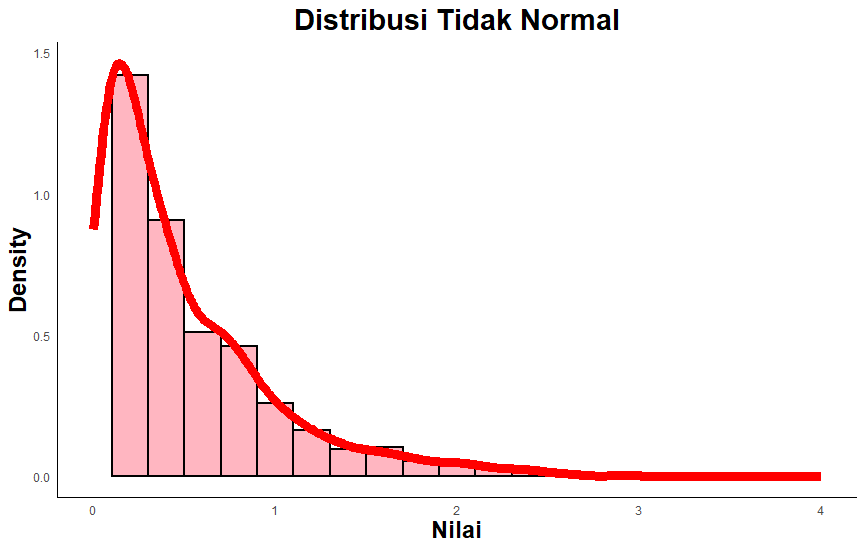
Data yang memenuhi asumsi parametrik dapat dianalisis lebih lanjut dengan statistik parametrik, sedangkan data yang tidak memenuhi asumsi dianalisis dengan menggunakan teknik statistik non-parametrik. Konsekuensi hasil analisisnya adalah pada generalisasi hasil analsis data. Pada statistik parameterik — karena data sampel terdistibusi normal — maka data tersebut dianggap mewakili populasi, sehingga setiap hasil analisis data tersebut dapat digenerasilasikan kepada populasinya. Dengan kata lain, hasil analisis data dianggap mencerminkan populasinya. Sedangkan jika data tidak memenuhi asumsi dan kemudian dianalisis dengan statistik non-parametrik, maka hasilnya tidak dapat disebut mencerminkan populasi, melainkan hanya menggambarkan sekelompok partisipan penelitian tersebut.
10.2 Metode Parametrik
Metode parametrik adalah pendekatan analisis statistik yang mendasarkan perhitungannya pada parameter populasi yang diestimasi dari data sampel, seperti mean, varians, dan standar deviasi. Metode ini beroperasi di bawah asumsi bahwa data berasal dari populasi dengan distribusi tertentu, umumnya distribusi normal, sehingga sifat-sifat distribusi tersebut dapat digunakan untuk membangun model matematis yang akurat. Proses analisis dalam metode parametrik biasanya melibatkan penggunaan rumus yang memanfaatkan parameter-parameter ini untuk menghitung ukuran efek, menguji hipotesis, atau membuat estimasi terhadap populasi.
Kelebihan utama metode parametrik adalah presisi dan kekuatan statistik yang tinggi, artinya metode ini lebih mampu mendeteksi perbedaan atau hubungan yang benar-benar ada dalam data, asalkan asumsi normalitas terpenuhi. Hal ini karena informasi yang digunakan berasal dari seluruh nilai data, bukan hanya peringkat atau kategori. Akan tetapi, jika asumsi distribusi dilanggar—misalnya data tidak normal atau mengandung outlier ekstrem—maka metode parametrik bisa menghasilkan estimasi yang bias dan kesimpulan yang menyesatkan. Oleh sebab itu, pengujian asumsi, khususnya normalitas, menjadi langkah krusial sebelum memilih metode ini.
10.3 Metode Non-Parametrik
Metode non-parametrik adalah pendekatan analisis statistik yang tidak bergantung pada asumsi bentuk distribusi tertentu dan tidak secara langsung menggunakan parameter populasi seperti mean atau varians dalam perhitungannya (Conover, 1999). Metode ini sering digunakan ketika data tidak memenuhi asumsi normalitas atau ketika data yang dimiliki berskala ordinal dan nominal, di mana informasi yang tersedia hanya berupa urutan atau kategori. Dalam praktiknya, metode non-parametrik banyak mengandalkan peringkat (ranking) untuk melakukan perbandingan antar kelompok atau mengukur hubungan antar variabel.
Kelebihan metode non-parametrik terletak pada fleksibilitasnya terhadap bentuk data —metode ini tetap dapat digunakan meskipun data terdistribusi miring, memiliki outlier, atau jumlah sampel relatif kecil. Selain itu, metode ini lebih “aman” digunakan jika peneliti tidak yakin bahwa asumsi parametrik terpenuhi. Namun, konsekuensi dari fleksibilitas ini adalah kekuatan statistik yang umumnya lebih rendah dibandingkan metode parametrik ketika asumsi normalitas sebenarnya terpenuhi. Artinya, metode non-parametrik mungkin kurang sensitif dalam mendeteksi perbedaan atau hubungan yang ada, sehingga hasil yang signifikan memerlukan efek yang lebih besar atau jumlah sampel yang lebih banyak.
Rangkuman perbandingan secara umum antara kedua metode analisis (parametrik vs. non-parametrik) dapat dilihat di Tabel 10.1.
| Aspek | Statistik Parametrik | Statistik Non-parametrik |
|---|---|---|
| Asumsi utama | Data berasal dari populasi yang berdistribusi normal. | Tidak memerlukan asumsi distribusi normal |
| Jenis data yang cocok | Data berskala interval atau rasio | Data berskala ordinal atau nominal, atau data interval/rasio yang tidak normal |
| Kelebihan | Memiliki daya statistik lebih tinggi jika asumsi normalitas terpenuhi | Lebih fleksibel terhadap pelanggaran asumsi dan dapat digunakan pada data yang tidak normal |
| Kekurangan | Data harus memenuhi asumsi-asumsi yang ketat | Umumnya memiliki kekuatan statistik lebih rendah |
| Konsekuensi praktis | Memberikan hasil yang lebih presisi pada data yang memenuhi asumsi normalitas | Memberikan hasil yang kurang sensitif dalam mendeteksi perbedaan atau hubungan yang ada |
🧪 Uji Normalitas Data (Shapiro–Wilk)
Generate data acak, hitung nilai W dan p-value, lalu tebak distribusinya.