Setelah data dikumpulkan dan diklasifikasikan, langkah selanjutnya adalah memastikan data tersebut layak untuk dianalisis. Proses ini dikenal sebagai data cleaning atau pembersihan data. Dalam tahap ini, peneliti melakukan analisis deskriptif awal untuk mendapatkan gambaran umum data, serta mengecek kemungkinan adanya missing valueatau outlier yang dapat memengaruhi hasil analisis. Pembersihan data bukan hanya soal menghapus skor-skor yang tidak wajar, tetapi juga tentang membuat keputusan yang tepat berdasarkan konteks penelitian. Dengan data yang bersih, hasil analisis akan menjadi lebih akurat dan dapat dipercaya.
5.1 Melakukan Analisis Deskriptif
Setelah peneliti memberi nama variabel dan mengidentifikasi jenis data sesuai dengan sifat masing-masing variabel, langkah berikutnya adalah melakukan analisis deskriptif awal terhadap data. Analisis deskriptif ini bertujuan untuk memastikan kualitas data sebelum masuk ke tahap analisis lebih lanjut.
Beberapa hal penting yang perlu diperhatikan dalam tahap ini antara lain:
Memeriksa sebaran skor
Peneliti perlu melihat apakah nilai total skor, minimum, maksimum, rata-rata (mean), dan simpangan baku (standar deviasi) dari setiap variabel berada dalam rentang yang sesuai dengan instrumen alat ukur dan sampel yang diteliti. Hal ini membantu mendeteksi adanya kesalahan input data atau anomali yang tidak sesuai dengan ekspektasi.
Memeriksa data hilang (missing values)
Identifikasi jumlah dan pola missing values pada setiap variabel sangat penting, karena dapat mempengaruhi validitas hasil analisis.
Mendeteksi nilai pencilan (outliers)
Nilai-nilai pencilan dapat mengindikasikan kesalahan pencatatan data atau variasi yang ekstrem di dalam sampel. Oleh karena itu, penting untuk mengidentifikasi outlier pada tahap awal, kemudian menentukan apakah nilai tersebut merupakan bagian dari variasi alami atau justru kesalahan yang perlu diperbaiki atau dikeluarkan dari analisis.
Dengan melakukan analisis deskriptif ini secara teliti, peneliti dapat memastikan bahwa data yang akan dianalisis lebih lanjut sudah bersih, valid, dan siap untuk digunakan, sehingga hasil penelitian menjadi lebih akurat dan dapat dipertanggungjawabkan.
5.2 Data Hilang
Terdapat sejumlah hal yang perlu Anda lakukan sebelum memulai analisis utama terhadap data Anda. Hal pertama adalah memeriksa apakah terdapat missing data (data hilang). Data hilang terjadi ketika terdapat pernyataan yang tidak diisi oleh seseorang yang menjawab survei atau kuesioner Anda. Partisipan mungkin tidak menjawab salah satu item pada survei karena berbagai alasan. Mereka mungkin melewatkan sebuah pertanyaan, enggan menjawab pertanyaan tertentu, atau merasa bosan dan berhenti mengisi survei. Ketidaklengkapan jawaban pada satu atau beberapa item ini menimbulkan masalah dalam analisis.
Data hilang dapat dikategorikan menjadi (1) missing completely at random (MCAR), (2) missing at random (MAR), atau (3) missing not at random (MNAR) (Buuren, 2018).
Missing completely at random (MCAR) berarti probabilitas sebuah data hilang sama besar untuk semua responden. Misalnya, seseorang secara acak melewatkan satu pertanyaan di survei Anda, sehingga data hilang itu benar-benar acak.
Jika probabilitas sebuah nilai hilang hanya sama dalam kelompok-kelompok tertentu yang didefinisikan oleh data yang teramati, maka data tersebut disebut missing at random (MAR). Karena itu, MCAR dan MAR adalah konsep yang saling terkait. Sebagai contoh, ditemukan bahwa responden yang tingkat stresnya tinggi cenderung melewatkan pertanyaan tentang tidur, mungkin karena merasa pertanyaan tersebut terlalu sensitif atau tidak relevan bagi mereka dalam kondisi stres.
Jika data hilang tidak memenuhi asumsi MCAR maupun MAR, maka disebut missing not at random (MNAR). Sebagai contoh, jika sejumlah besar peserta sengaja melewati satu pertanyaan tertentu pada survei, maka hal itu tidak terjadi secara acak. Kemungkinan ada alasan tertentu mengapa pertanyaan itu dilewati, misalnya karena pertanyaan kurang jelas, terlalu pribadi, atau tersembunyi di bagian bawah halaman.
Terdapat sebuah uji untuk mengetahui apakah data hilang secara acak atau tidak, yaitu Little’s MCAR test. Secara sederhana, jika hasil uji tidak signifikan, maka data hilang kemungkinan terjadi secara acak. Sebaliknya, jika hasil uji signifikan, ada kemungkinan data hilang karena alasan sistematis atau tidak acak.
Lalu, apa yang bisa dilakukan peneliti untuk menangani data hilang? Secara umum, terdapat dua cara utama untuk menangani data hilang, yaitu:
Penggantian dengan rata-rata (mean replacement). Dalam prosedur ini, Anda mengganti titik data yang hilang dengan nilai rata-rata variabel tersebut. Namun, teknik ini hanya disarankan jika data hilang secara acak (at random) dan proporsinya kurang dari 5% pada variabel yang bersangkutan.
Imputasi majemuk (multiple imputation). Teknik ini dilakukan dengan bantuan program statistik yang Anda gunakan, yang menganalisis pola data dan menetapkan nilai untuk variabel yang hilang pada kasus tertentu. Nilai ini didasarkan pada jawaban sebelumnya pada variabel terkait, serta jawaban tidak hilang pada variabel tersebut di kasus lain. Disarankan menggunakan metode ini jika data hilang secara acak dengan proporsi antara 5–10% dari total respons pada variabel tersebut.
5.3 Data Pencilan
Salah satu hal yang perlu diperhatikan saat menganalisis data adalah pengaruhoutlier — yaitu data yang nilainya sangat tinggi atau sangat rendah dibandingkan data lainnya — terhadap hasil keseluruhan. Contohnya, jika Anda bertanya kepada orang-orang tentang berapa cangkir kopi yang mereka minum dalam sehari, sebagian besar jawabannya mungkin berkisar antara nol hingga empat cangkir. Sebaran ini disebut dengan sebaran jawaban yang normal. Namun, jika ada satu orang yang menjawab bahwa ia minum 17 cangkir kopi sehari, maka jawaban ini bisa dianggap sebagai outlier bila dibandingkan dengan partisipan lainnya.
Kita bisa mengasumsikan bahwa orang tersebut memang memiliki masalah dengan kafein atau mungkin salah memasukkan jawaban. Apa pun alasannya, jawaban ini bisa meningkatkan rata-rata (mean) konsumsi kopi dalam sampel, padahal sebetulnya jawaban ini tidak mewakili kebiasaan rata-rata peminum kopi.
Ada beberapa cara secara statistik untuk mengidentifikasi outlier dalam kumpulan data Anda (Tabachnick & Fidell, 2019):
Mengubah jawaban peserta untuk setiap variabel menjadi skor-z (z-score).
Skor-z adalah transformasi dasar untuk membandingkan jawaban peserta dengan distribusi standar yang memiliki rata-rata 0 dan standar deviasi 1.
Jika suatu jawaban memiliki skor-z lebih besar dari +3.3 atau kurang dari -3.3, maka jawaban ini dianggap sebagai outlier.Memvisualisasikan data menggunakan box plot atau bar graph, lalu melihat secara langsung apakah ada data yang tampak menyimpang jauh. Lihat Gambar 5.1 untuk visualisasi dari outlier menggunakan box plot.
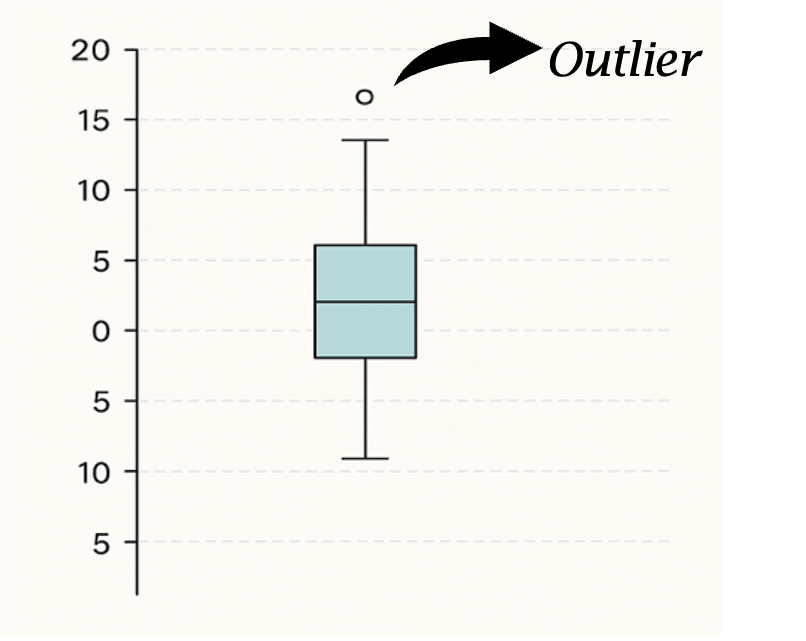
Setelah menemukan outlier, Anda punya dua pilihan (Dancey & Reidy, 2017):
Tetap menyertakan dalam analisis jika Anda menganggap outlier ini bukan kebetulan.
Menghapus dari analisis jika outlier ini muncul karena alasan yang tidak valid, misalnya kesalahan input atau jawaban yang tidak realistis.
Jika jawaban outlier tersebut tidak masuk akal dalam konteks pertanyaan, atau terlalu ekstrem tanpa alasan yang jelas, maka sebaiknya dianggap sebagai jawaban tidak valid (spurious response) dan dihapus dari analisis. Namun, jika jawaban tersebut masih masuk akal atau hanya sedikit melampaui batas skor-z (± 3.3), Anda bisa mempertimbangkannya sebagai outlier yang valid dan tetap menyertakannya dalam analisis.